The Sovereign Pathology Fabric: Architecting Decentralized Foundation Models for Clinical Diagnostics
A mathematical and physically impenetrable system designed for the highest levels of healthcare compliance.
Modern clinical diagnostics operates at the absolute frontier of high-dimensional data acquisition. A single gigapixel Whole Slide Image (WSI) routinely exceeds 10 gigabytes. Yet, when we attempt to deploy deep foundation models to this high-resolution data, we are forced into a profound structural impasse.
The current default in medical AI is the Centralized Cloud SaaS model. But uploading gigapixel WSIs to centralized cloud repositories triggers a catastrophic "Data Gravity" failure. Wide-area network (WAN) bandwidth limitations and severe egress costs render real-time clinical workflows non-viable. More critically, it demands that healthcare institutions surrender direct sovereignty over raw patient data—generating irreconcilable compliance conflicts under HIPAA, GDPR, and national data residency mandates.
The alternative—isolated on-premises silos—preserves privacy but severely limits the model's capacity to generalize. These models quickly become over-indexed to specific digital scanners, chemical staining formulations, and regional demographics. Even traditional Hub-and-Spoke Federated Learning introduces a central coordinator that acts as a dangerous single point of network failure and a primary target for data interception.
The Sovereign Pathology Fabric represents a fourth path: a fully decentralized, peer-to-peer (P2P) clinical intelligence mesh that completely eliminates reliance on centralized orchestrators or cloud aggregators.
Local Inference: Saturating NVIDIA Blackwell Hardware
The execution of this architecture relies on deploying dedicated, on-premises AI compute clusters directly within the local institutional firewall. The platform is engineered specifically to saturate the performance of the NVIDIA Blackwell (GB10) architecture.
Rather than relying on high-latency cloud data centers, the fabric exploits local hardware to achieve microsecond inference latencies directly on institutional networks. This is achieved through three critical hardware optimizations:
- GPUDirect Storage (GDS) & Zero-Copy Tiling: To maximize throughput, the architecture utilizes GDS to establish a direct, zero-copy memory path from local high-speed NVMe arrays straight to GPU VRAM. This completely bypasses host CPU and system memory bottlenecks during gigapixel image interrogation.
- Paged Memory Allocation: The system processes high-resolution WSI tiling via advanced paged memory schemes to manage heavy multi-specialty clinical workloads seamlessly.
- Native FP8 Quantization: Gradient updates and weight slices are quantized to Blackwell-native FP8 (E4M3) before network transmission. This achieves a 50% reduction in mesh bandwidth requirements without any loss in diagnostic precision.
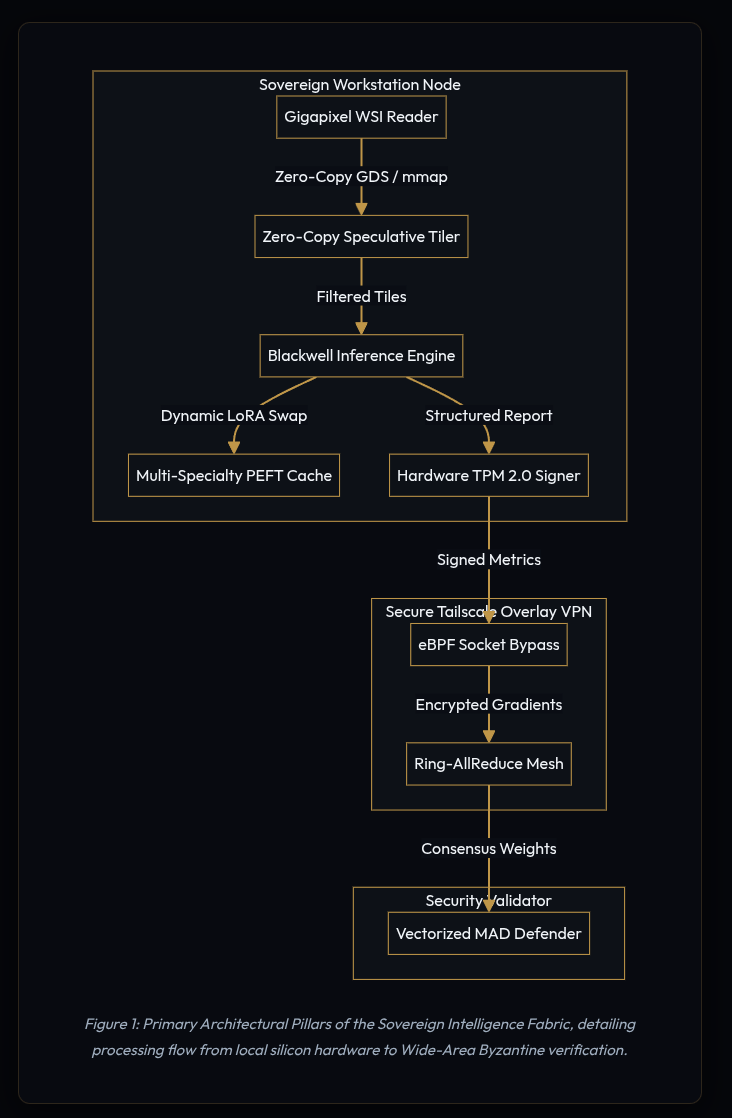
Core Topology: Decentralized Ring-AllReduce
Intelligence should be shared; raw data should not.
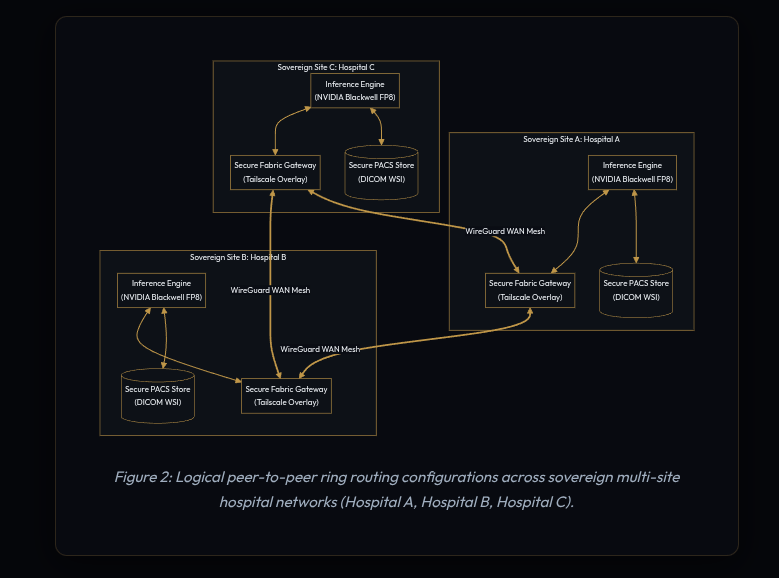
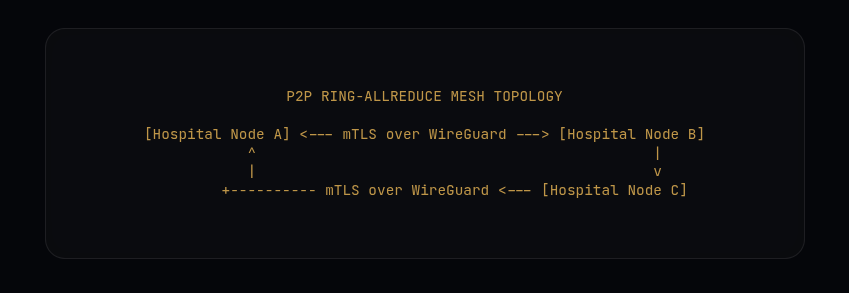
To facilitate global model optimization across high-latency WAN links without a central orchestrator, the fabric organizes sovereign nodes into a dynamically routing Ring-AllReduce topology. This completely removes the central server as a single point of failure and bandwidth bottleneck.
The algorithm executes two distinct phases across $N$ nodes via per-instance asyncio.Queue wiring:
- Phase 1 — Scatter-Reduce ($N-1$ steps): Each step, Node $i$ sends data chunks to the next peer and awaits the incoming chunk from the previous peer. The received chunk is accumulated and ultimately normalized by dividing by the number of nodes to produce the per-chunk mean.
- Phase 2 — All-Gather ($N-1$ steps): Each step, Node $i$ sends the fully reduced chunk forward and overwrites its local slice with the incoming, already fully reduced chunk. After $N-1$ steps, every node holds the complete global consensus tensor.
Through a custom gRPC Federated Averaging (FedAvg) mesh communicating via Tailscale WireGuard VPN tunnels, nodes synchronize Low-Rank Adaptation (LoRA) adapter weights directly with peer nodes, bypassing central cloud aggregators entirely. If an individual clinical node goes offline during a synchronization cycle, per-step timeouts (60 seconds) allow the ring to continue with local slices, logging a warning rather than hard-failing. The remaining mesh merges the missing node's contributions asynchronously once its connection is verified and restored.
Beyond LoRA: Weights and Region Attribution (WaRA)
Federated averaging updates the model mathematically, but clinical accountability requires semantic explainability. To achieve this, the architecture introduces the Weights and Region Attribution (WaRA) pipeline.
When an institutional node crosses designated readiness thresholds (such as 500 signed cases and 2,000 annotations), the system triggers a background coroutine migrating from LoRA to WaRA fine-tuning. WaRA fine-tunes adapters using attribution-weighted gradients.
Post-aggregation, the system calculates layer-wise consensus update norms:
Δ = ||Wconsensus - Wlocal||2
Layers that accumulated the most consensus delta across Ring-AllReduce rounds are flagged as clinically dominant. WaRA dynamically propagates these attribution scores back to WaraRegion ontology layers inside a localized Neo4j Clinical Knowledge Graph. Each LoRA parameter gets its own parameter group where learning rates are scaled proportionally to its attribution score, automatically focusing the foundation model's capacity on clinically dominant features.
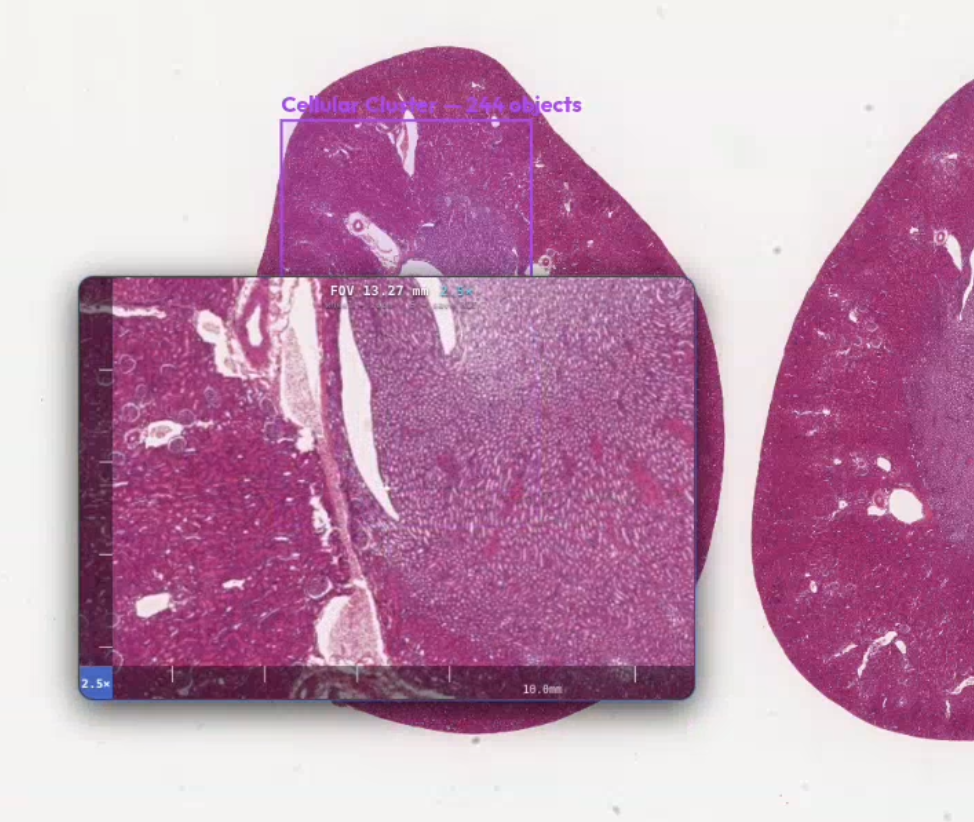
The Tri-Model Neuro-Symbolic Pipeline
A monolithic "black box" model is architecturally inefficient for multi-modal clinical workloads. The Sovereign Pathology Fabric relies on a three-model pipeline that separates feature extraction, visual description, and clinical reasoning into isolated, specialized services:
- The Vision Encoder (Prov-GigaPath): Operates directly on raw WSI tile pixels at 0.5 μm/pixel. It extracts 1,536-dimensional feature vectors per patch via a pre-trained ViT-Giant encoder, utilizing Multiple Instance Learning (MIL) to mean-pool logits across the top-N regions.
- The Visual Patch Analyst (MedGemma-4B-IT): A multimodal model built with a SigLIP vision encoder. Running at INT8 on Blackwell, it receives the top patches as base64 JPEGs alongside GigaPath confidence context to produce granular, patch-level histological descriptions detailing cell architecture, nuclear atypical characteristics, and stromal features.
- The Clinical Reasoning Engine (MedGemma-27B): A highly optimized, text-only language model. It receives no image tensors. Instead, it ingests the structured text findings (aggregated GigaPath logits, 4B-IT visual descriptions, Cellpose morphometrics, and pathologist clinical context) to synthesize the final consolidated diagnostic report and synoptic staging.
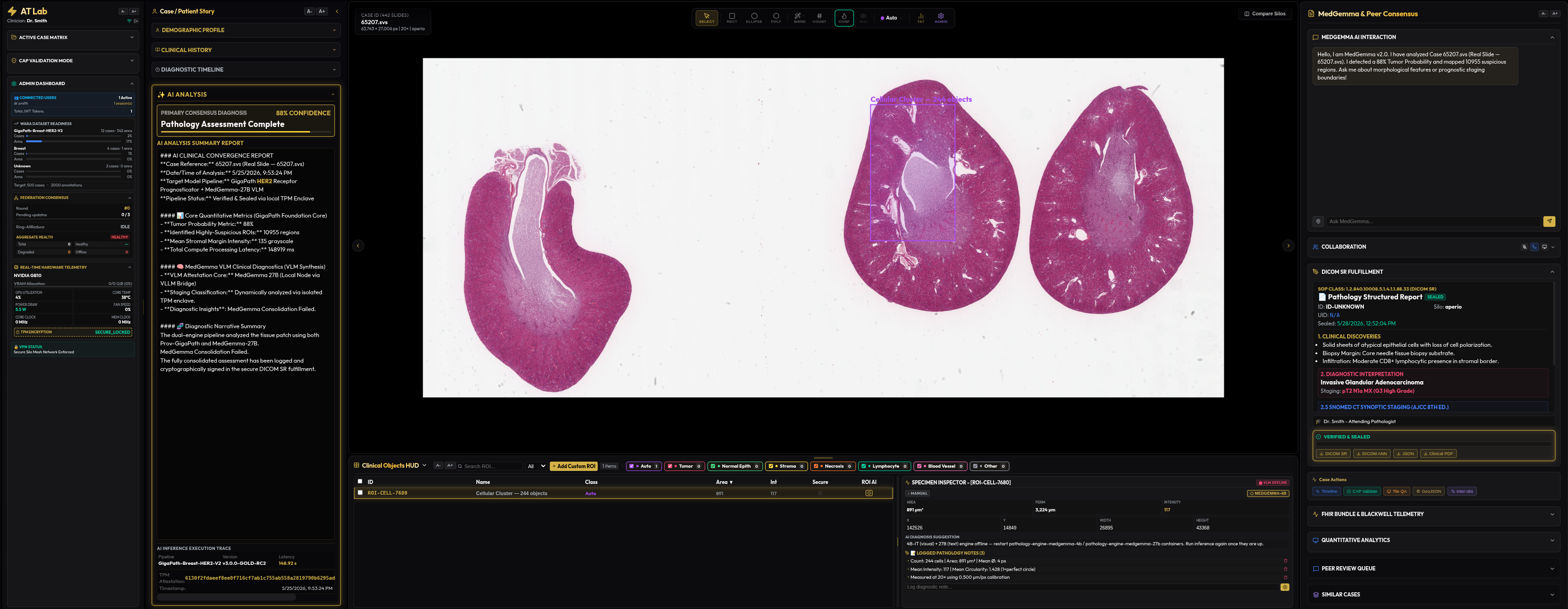

Dynamic Multi-Specialty PEFT Routing
To avoid massive VRAM wastage caused by loading redundant base models for independent clinical departments, a single shared foundation model is loaded into secure memory space. Specialty-specific adapters (Pathology, Radiology, Dermatology, Oncology, Odontology) are dynamically hot-swapped as compact Parameter-Efficient Fine-Tuning (PEFT) layers.
Before deep inference executes, an automated pre-inference router determines the optimal adapter using a cascading 3-Tier fallback ladder:
- Tier 1 (Clinical Context): Pathologist-entered free-text diagnostic notes are parsed for keywords and mapped to a SNOMED-CT disease concept ID via Neo4j to resolve the matching adapter.
- Tier 2 (Metadata Scan): If free text is empty, the engine parses DICOM elements (such as
BodyPartExamined) or OpenSlide attributes to execute the mapping. - Tier 3 (Visual Triage): If metadata is completely absent, the engine extracts a low-resolution thumbnail from the lowest pyramid layer of the slide and runs a fast triage prompt on MedGemma-4B-IT to visually classify the organ, tissue, and disease origin.
Resolved routes are cached in Redis with a 24-hour TTL (adapter_route:{wsi_id}), allowing subsequent reads to bypass triage and resolve in under 1 millisecond. To protect the VLM thread pool from burst loads, a per-adapter concurrency semaphore limits active inferences, while a Least-Recently-Used (LRU) cache triggers automated CUDA VRAM sweeps to prevent Out-Of-Memory (OOM) failures.
Clinical-Grade Zero-Trust Security Framework
Data security in a distributed clinical environment cannot rely on software policies alone; it must be bound to physical silicon. The fabric implements an airtight, three-layer zero-trust stack:
- Layer 1: Network Isolation via Tailscale mTLS: All inter-silo traffic is forced through encrypted WireGuard tunnels. Socket-layer redirection via an eBPF C filter inspects packet headers to auto-detect Layer 3 raw IP packets versus Ethernet-encapsulated frames, enabling kernel-bypass packet acceleration over virtual overlay network cards.
- Layer 2: Hardware-Bound Integrity (TPM 2.0 Signatures): Every diagnostic report (DICOM-SR) and federated update is cryptographically signed by the node's local hardware TPM 2.0 module. To prevent signature replay attacks, the signing routine prepends a high-entropy 16-byte random nonce and a Unix timestamp to the payload before hashing, making every signature unconditionally unique.
- Layer 3: Confidential Computing (TEE VRAM Shielding): Base weights and active patches are decrypted exclusively within hardware-protected memory spaces inside the GPU enclaves. This isolates sensitive data from host system administrators or adjacent container workloads.
- Vectorized Byzantine Protection: Peer updates are guarded against adversarial model poisoning via a Multi-Krum validator. Pairwise Euclidean distance matrices are computed in parallel in C++ via PyTorch's
torch.cdistoperator, while a robust Median Absolute Deviation (MAD) gate isolates malicious weight injections:
MAD = median(|xi - median(x)|)
Conclusion: The Automated Diagnostic Mesh
By shifting the paradigm from centralized cloud aggregation to a hardware-accelerated, peer-to-peer fabric, the structural limitations of distributed medical AI are systematically resolved. The architecture proves that high-dimensional medical imaging can achieve collective, global intelligence without sacrificing institutional data sovereignty, network bandwidth, or cryptographic security.
The future of clinical intelligence isn't in the cloud. It’s in the Fabric.